Both sign language and verbal (also referred to as spoken) language are full forms of language (full stop!). They just use different forms of physical expression, known as modalities. Verbal language involves the oral-auditory modality, which is based on the sounds that humans can produce with their vocal tracts and understand with their hearing. Sign language, on the other hand, uses the visual-gestural modality. The visual-gestural modality relies on the purposeful movement and framing of the hands, as well as the upper body, head, and facial expressions, and it is understood with people’ sense of vision. However, despite these seemingly different processes of language, to the brain, both language modalities are actually very similar. Signing and auditory speech processing engage many of the same networks in the left hemisphere of the brain. Using either speech sounds or signs (or both!), people can convey complex and abstract information built out of smaller linguistic pieces, using grammatical rules.
The visual-gestural modality and the oral-auditory modality contain the same grammatical characteristics such as phonology, morphology, and syntax. Oral speech is formed by the combination of phonemes, which are speech sounds created by an individual’s mouth such as tongue placement and lips shape; similarly, the “phonemes” units of sign language are created by an individual’s hands with their shape, movement, and position with respect to their body. However, there is discussion among researchers whether to continue referring to these units as “phonemes” since it comes from the Greek root word “phone,” meaning sound. Some researchers instead refer to these small units of sign as “cheremes”.
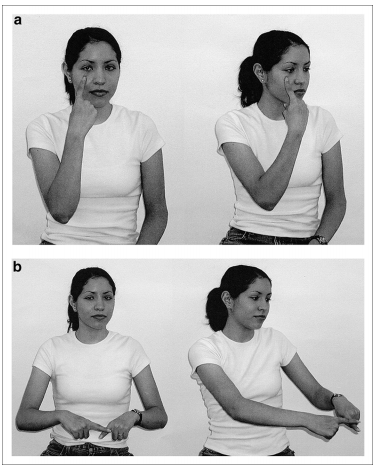
Although many similarities exist between both language modalities, there are certainly differences as well. For example, the connection between most words and their meanings is arbitrary (e.g. the way the English word “cup” sounds doesn’t have anything to do with a cup — although some words, like “cockadoodle-doo” do sound like what they mean!). While most signs are arbitrary, in sign language many words create a visual form of the word, and thus some researchers believe there is slightly more iconicity in sign language than in spoken language. Unlike oral-auditory language, the visual-gestural modality is also able to use facial expressions as part of grammar structure. For example, in American Sign Language, raising or lowering the eyebrows can indicate that a sentence is a question. Furthermore, in the oral-auditory modality, words and sentences have to follow one another in linear time order (we can’t say multiple words at the same time). Yet, the visual-gestural modality is not limited to a linear sequence: sign languages can use space to combine signs and gestures simultaneously to create meaning.
Historically, many hearing people, including educators, have mistakenly believed that the oral-auditory modality of language was “superior” for communication and more complex than the visual-gestural modality– even that sign languages weren’t “real” languages at all. Because of these harmful attitudes, Deaf and Hard-of-Hearing individuals have often suffered punishment for using sign languages at school, or have been restricted to using only spoken languages, which might not be accessible to them at all. However, signed languages are natural human languages, and children exposed to sign language follow a similar language learning path to children learning a spoken language. Deaf and signing activists have worked hard to correct the negative misconception towards sign language, but the harmful effects of prioritizing the oral-auditory modality continue today, including by in the world of language research. The most predominant sign language in the United States and also most thoroughly studied sign language is American Sign Language (ASL); though now there are many researchers studying other sign languages around the world, trying to make up for the lack of prior research.
Verbal and sign languages use physically different modalities: oral-auditory and visual-gestural respectively. Despite their physical differences, both of these language modalities are processed similarly in the brain, have complex linguistic patterns, and ultimately give people the same rich communicative ability.

Natalie chou
Author
Natalie is a junior at Duke where she plans to pursue a Program II to explore her academic interests in both documentary studies and child health. After Duke, she hopes to attend medical school and continue working with children through healthcare and research. She is most interested in child language development, particularly in regards to multilingualism. Natalie enjoys all things tennis, singing, hiking, photography/videography, and food exploring.
Elika Bergelson
PRincipal Investigator