If you’re a parent, you’ve probably noticed how your baby’s sounds change over time. At first, they make simple consonant- or vowel-only sounds like “mmmm” and “aaa”. But then something exciting happens: they start combining consonants and vowels in sounds like “bababa”. These combinations are a big deal for language development. They are a sign that your little one is getting closer to saying their first word!
But when does this exciting milestone happen? Every baby develops at their own pace. While most babies start combining consonants with vowels around 6-8 months, some children, including those with neurodevelopmental diagnoses like Down syndrome, may start at different times (Cychosz et al., 2021; Long et al., 2023). To follow this development, researchers measure the proportion of consonant-vowel sounds: out of all the sounds a baby makes, how many are the “bababa” type? By measuring this proportion over time, researchers can track how a baby’s language skills are progressing.
What’s the problem? One way researchers can measure baby babbles is to have them come into the lab and play, and just wait for them to make whatever sounds they make. Another more “natural” way to do this is to send families home with little audio-recorders that capture a full day of their child’s natural sounds (different kinds of babbling, crying, burping, you name it). Here’s the catch: someone has to then sit and listen to hours of these recordings, noting down and categorizing every sound the child makes as being either the “aaa” or “bababa” type. It can take a trained researcher up to half an hour just to fully annotate a single minute of audio (Casillas, Brown, & Levinson, 2020). That means analyzing just one hour would take an entire work week! Clearly, we need a faster solution.
What if we could teach computers to recognize baby babble? That’s exactly what our team tested. We used a computer program designed to automatically identify the types of sounds produced by children (Zhang et al., 2025). We collected recordings from 50 two-year-olds from five groups: 1) kids with 1) Fragile X syndrome, 2) Down syndrome, and 3) Angelman syndrome; 4) kids with an autistic sibling; and 5) kids with no neurodevelopmental diagnosis. First, we had a (very dedicated and hardworking!) human expert listen to the recordings and label every sound. Then, we had our computer program analyze the same recordings to see if it would give us the same results as the human about what kinds of babbling the baby is doing.
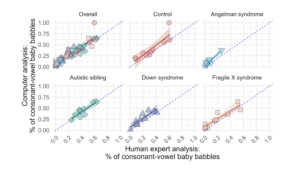
What did we find? The results were very encouraging! To visualize this, we created a graph comparing what the human thought compared to what the computer identified. Each dot represents one child, and the closer the dots are to the diagonal dashed line, the more the computer and human agreed. Looking at the “Overall” panel, you can see most dots cluster near thethat diagonal line, indicating strong agreement. What’s particularly exciting is that there was similarly strong agreement across all groups, meaning that the computer program performs equally well on different populations.
Why does this matter? This research could make a real difference in several ways. If we can accurately measure how a child’s babbling develops, we might identify children who could benefit from speech support earlier than ever before. For children already receiving speech support, this technology could also help measure concrete changes in their babbling patterns over time.
Looking forward. While we’re still in the early stages, these first results are very promising! Every child’s path to language is unique, but having better measurement tools to understand and support that journey benefits everyone – parents, clinicians, educators, caregivers, and most importantly, the children themselves as they work toward those exciting next stages of language development.
References
Cychosz, M., Cristia, A., Bergelson, E., Casillas, M., Baudet, G., Warlaumont, A. S., Scaff, C., Yankowitz, L., & Seidl, A. (2021). Vocal development in a large‐scale crosslinguistic corpus. Developmental Science, 24(5), e13090.
Long, H. L., Christensen, L., Hayes, S., & Hustad, K. C. (2023). Vocal Characteristics of Infants at Risk for Speech Motor Involvement: A Scoping Review. Journal of Speech, Language, and Hearing Research, 66(11), 4432–4460.
Casillas, M., Brown, P., & Levinson, S. C. (2020). Early language experience in a Tseltal Mayan village. Child Development, 91(5), 1819-1835.
Zhang, T., Suresh, M., Warlaumont, A. S., Hitczenko, K., Cristia, A., & Cychosz, M. (2025). Employing self-supervised learning models for cross-linguistic child speech maturity classification. Interspeech.

Lydia Wiernik
Author
Lydia studied Linguistics at the University of Edinburgh, where their dissertation investigated the influence of bimodal bilingualism on hearing individuals’ cognitive strategies for visuospatial perspective-taking. Since graduating, Lydia has been researching the neurobiology of sign language at the Max Planck Institute for Human Cognitive and Brain Sciences (Leipzig, Germany) and helping develop intraoperative linguistic testing batteries for awake craniotomy with the Brain, Language, and Behaviour Lab (Bristol, UK).